超越谷歌微软,阿里达摩院AI预训练模型M6参数规模破10万亿
11月8日消息,阿里巴巴达摩院公布多模态大模型M6最新进展,其参数已从万亿跃迁至10万亿,规模远超谷歌、微软此前发布的万亿级模型,成为全球最大的AI预训练模型。同时,M6做到了业内极致的低碳高效,使用512块GPU在10天内即训练出具有可用水平的10万亿模型。相比去年发布的大模型GPT-3,M6实现同等参数规模,能耗为其1%。
【什么是超大规模预训练模型】
目前,人工智能正迅速普及并应用到人们的日常生活,但仔细观察会发现,这些技术主要集中在“感知层面”,比如听觉、视觉等。但需要外部知识、逻辑推理的“认知层面”,人工智能尚处于初级阶段。
“认知智能”被认为是下一代人工智能的关键性突破。而超大规模预训练模型则被认为是认知智能的基础设施。
当前,企业应用AI技术面临前期投入大、开发时间长等痛点,AI技术高昂的使用门槛将绝大多数企业拒之门外。Gartner的研究报告显示,37%的企业已经或即将部署AI模型,但仍有大量中小企业未享受到人工智能技术带来的利好。大规模预训练模型的出现或将彻底改变人工智能的应用现状。
大规模预训练模型基于复杂的预训练目标和庞大的模型参数,将丰富的知识存储到大量参数的隐式编码中,使其能够完成多种下游任务,即便是新任务,也能够通过动态学习来完成。
借助大规模预训练模型, 企业应用AI技术的前期投入将大幅下降,其不再需要前期就投入大量资金和时间研发定制化模型。

2020年8月,GPT-3模型的面世可谓人类AI史的里程碑事件。GPT-3是美国非盈利机构OpenAI发布的GPT第三代模型,被誉为“最接近通用人工智能”的模型。GPT-3不仅支持多种不同类型的任务, 包括改语法错误、写文章( 写诗) 、聊天、算数、答题、翻译等, 还能够通过小样本动态学习, 解决从未遇到过的任务, 从而具备成为通用解决方案的能力。
【阿里达摩院的超大规模多模态预训练模型M6】
鉴于大规模预训练模型的强大与高效, 国内头部科研机构如阿里、华为、智源研究院也都先后发布了自研的大规模预训练模型。
其中,M6是由阿里达摩院联合清华大学研发,中国首个万亿参数的超大规模多模态预训练模型。

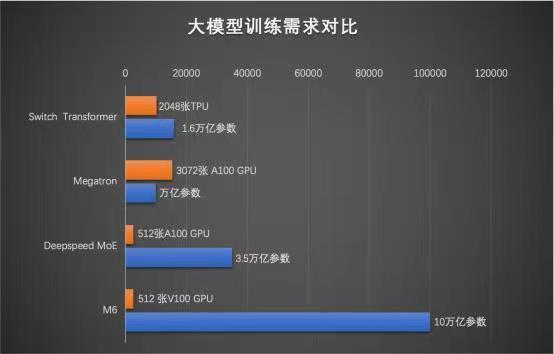
据悉,M6的优势在于将大模型所需算力压缩到极致,通过一系列技术突破,达摩院和阿里云只用了480块GPU就训练出了M6,相比英伟达用3072块GPU训练万亿模型、谷歌用2048块TPU训练1.6万亿模型(1 TPU约等于2~3GPU),M6省了超过八成算力,还将效率提升了近11倍。
阿里达摩院的M6定位是主打多模态、多任务能力,目标是成为全球领先的具有通用性的人工智能大模型。
【M6的商业化应用】
随着M6参数规模的扩大,AI的认知和创造能力不断升级。阿里研究人员发现,M6在绘画、写作、问答、文字生成图片领域均有惊人的表现,可以生成1024*1024分辨率宛如实物的高清图片,比此前海外公司OpenAI最高纪录提升4倍。
不仅如此,M6更是首个真正进入商用的多模态通用大模型。目前,M6已作为AI小助理在阿里新制造平台犀牛智造上岗,可实现快速设计、试穿效果模拟。M6还已应用在支付宝、淘宝等平台,参与跨模态搜索、文案撰写、图片设计等工作。
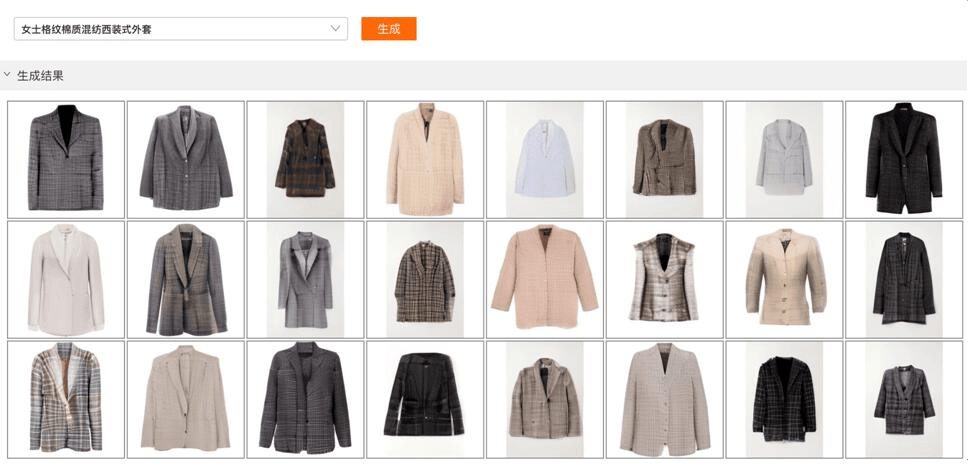
M6根据文本内容,自动设计特定风格图片
举个例子,按照淘宝目前的搜索系统,用户在淘宝上搜索商品名称或类别时,通常会用到关键词搜索,但对于用户一些十分特别的商品特征需求,商家未必能够把特征关键词全部罗列出来。比如,用户可能想要寻找一个表面凹凸的咖啡杯,但商家一般不会把这样的细节写在商品描述中,用户难以快速搜索到这种商品。
但多模态大模型M6可以做到,目前M6已建立了从文本到图片的匹配能力。这意味着,AI通过识别图片就可以知道商品的所有细节特征,AI会把这些细节特征记录成文本,用户无论搜索什么“奇葩”的特征,系统都能帮用户找到相对应的商品。
未来,M6或将建立从文字到视频内容的认知能力,为搜索形态带来变革。
