深度学习框架简史:PPT格局初现,中国占有一席
Alter聊IT撰文 / 张贺飞
编辑 / 沈洁
“科技无国界”的幻想,因为东欧的战火被彻底击碎。
苹果、谷歌、Facebook、SAP、微软等科技巨头,早已有了实际的行动。单单是Apple Pay和Google Pay的停用,就已经影响了数千万人的生活秩序,而GitHub、Node、React等开源平台针对俄罗斯开发者的严格限制,则给不少企业的产品开发、商业运作蒙上了一层不确定的阴影。
在这样的语境下,开源软件的自主可控再度成为舆论场上的焦点,特别是作为AI基础技术的深度学习框架,更是聚焦了无数开发者的关切。深度学习框架属于AI的底层技术创新,一旦这些技术被套上枷锁,千行百业的智能化转型将被制约,甚至会影响国内第四次工业革命的进程。
可能在不少人的认知里,深度学习框架还是一个陌生的词汇,对其所扮演的角色以及重要性仍处于懵懂状态。我们不妨从盘点和回顾的视角,梳理下深度学习框架的周期演变,在从学术圈走向工业界再到产业化的历程中,找寻属于中国企业的机会和挑战到底在哪里。
01
学术时代:学者们的“刀耕火种”
想要讲清楚深度学习框架的起源,难免要花上一定的篇幅,简单概述下人工智能技术的进化历程:
早在1943年,美国心理学家麦卡洛克和数学家皮茨就提出了人工神经网络的概念,比世界上最早的通用计算机的出现还早了3年时间。
其后出现了不少新概念和新模型,但人工智能的进展始终差强人意。直到杰弗里·辛顿在2006年发表了一篇题为《一种深度置信网络的快速学习算法》的文章,其中的核心理念是利用 GPU 来加速训练,大幅提高了神经网络的学习速度。
时间来到2012年,师从杰弗里·辛顿的多伦多大学研究生艾力克斯·克柴夫斯基,在当年的 ImageNet 挑战赛中使用一种新的深度神经网络架构进行训练,在 ImageNet 数据集上达到了 SOTA 精度,远超一些学术界的顶级团队。这种深度神经网络架构,就是后来大名鼎鼎的AlexNet,并在全球范围内掀起了深度学习的热潮。

图:杰弗里·辛顿
在机器学习大行其道的时候,几乎没有一种算法在大量的问题上取得压倒性的优势,大多数业务问题可以通过大数据和算法结合的经典方式解决。可到了深度学习的时代,数据、算法和算力都在爆炸式增长,为了提高工作的效率,一些研究者开始编写深度学习模型的几个必要过程,把前人的研究成果不断沉淀其中,后来人可以直接调用某些成果,大幅降低了编写深度学习模型的门槛。
“深度学习框架”的概念由此诞生,迅速涌现出了Theano、Caffe、Torch等多款深度学习框架,至今仍是人工智能圈子里的热门话题。
科技文明的每一次跃进,都离不开个体的灵光乍现,人工智能又恰恰是一个标准的众创型技术。所以早期深度学习框架的缔造者,往往被赋予一种特殊的光环,并随着时间的推移不断放大其中的价值。可回头来看,这些盛名在外的早期框架也有着时代的局限性,所能解决的往往是一类问题,而且有着鲜明的学术色彩。
比如艾力克斯·克柴夫斯基就写过一套名叫Cuda-Convnet的深度学习框架,可以在GPU上快速跑神经网络,却不怎么重视工程设计,也谈不上模块化和抽象化能力,单纯是为了搞科研、出论文。
深度学习开源工具的鼻祖Theano,严格地说是一个擅长处理多维数组的 Python 库,用于高效解决多维数组的计算问题。相较于当前深度学习框架的功能,Theano更像是一个数学表达式的编译器。
值得一提的是,在深度学习框架“刀耕火种”的日子里,中国的学者们并没有缺席。百度2013年成立了深度学习研究院,Caffe等框架的主导者中都有华人的身影。暗合科技创新的潜在趋势,中国不再是创新进程中的跟随者,这一次我们也站在了最前沿的领域。
02
商业时代:科技巨头“闯入江湖”
2015年是深度学习框架的转折点,这年前后发生了两件深刻影响到人工智能历史进程的重要事件:
一件发生在学术领域。微软亚洲研究院的学者提出了著名的ResNet架构,影响力丝毫不输当年的AlexNet,不仅在ImageNet的准确率上再创新高,也让学术界外的工业界形成了一个共识,即深度学习将成为下一个重大技术趋势。
另一件发生在围棋圈。谷歌旗下DeepMind团队开发的AlphaGo,和韩国著名棋手李世石进行了一场围棋人机大战,最终以4比1的总比分获胜。由此出圈的不只有AlphaGo和谷歌,深度学习的概念也被越来越多的“行外人”知晓。

后知后觉的话,这两起事件都有其吊诡之处。ResNet在2015年的原始残差网络的结果一度被质疑无法复现,而AlphaGo的围棋挑战赛本身就有作秀的嫌疑。草蛇灰线,伏脉千里,不寻常的背后是科技巨头们的精妙布局。
2013年3月,谷歌以4400万美元的价格收购了杰弗里·辛顿创建的DNNResearch,这场交易的重心并不是什么新业务,而是辛顿本人和他的两位学生。据说百度也参与了这场“拍卖”,并坚持到了辛顿做出选择的最后一刻。
谷歌疯狂“敛才”的原因,在2015年11月被揭晓:谷歌大脑团队开发的深度学习框架TensorFlow正式开源,杰弗里·辛顿为此做了很多贡献。谷歌的另一位研究员弗朗索瓦·乔莱特,几乎独自完成了Keras框架的开发,为谷歌再添一条护城河。
遗憾错失杰弗里·辛顿的百度也没闲着,2012年开始大规模采购和建立GPU运算集群,是国内最早投入研究深度学习平台的企业,培养和吸纳大批AI顶尖人才,内部打磨重构多年的PaddlePaddle,也在2016年正式开源,后来取了一个中文名字叫“飞桨”。
同样对深度学习框架野心勃勃的Meta(原Facebook),走了一条循序渐进的路。先是控制了著名的深度学习库Torch,然后用从Python替换了Lua语言,对Tensor上的全部模块进行重构,并在2017年初以PyTorch的身份正式开源。同时还搞了Caffe2项目,像谷歌一样开启了双平台战略。
这个阶段可以说是深度学习框架的第一次“百家争鸣”,Amazon主导的MXNet、微软背书的CNTK陆续出现在开源名单上。深度学习框架不再是学者们的自留地,科技巨头们接过了主导市场的权柄。
相对应的是新旧交替的一幕。
Alpha Go最初是基于Torch开发的,但在TensorFlow开源后立即进行了迁移;Theano的开发团队在2017年9月宣布停止维护和更新,从此退出了历史舞台;微软的CNTK经历了一定时间的奋力追赶后,最终在2019年宣布停止维护;Keras后来被TensorFlow收编,Caffe2被PyTorch接纳......
还有很多不知名的深度学习框架,还没来得及被外界所熟知,就被埋在了人工智能高速增长所掀起的尘土中。相比于豪掷千金买技术、团队、人才的巨头,很多初创企业常常被各种因素束手束脚,结局在一开始就注定了。
03
应用时代:“剩者为王”的竞速赛
正如人类历史屡屡被验证的趋势,深度学习框架经历过短暂的激烈角逐后,也呈现出了“寡头化”的局面。
背靠谷歌这座开源大山,TensorFlow在开源伊始就表现出了主场优势,大批学者自觉转移了阵地。按照谷歌天才科学家杰夫·迪恩在一次演讲中的说法:2016年TensorFlow的论文引用次数呈现出指数级暴涨。
不过,谷歌无意在学术圈画地为牢,早早将目光瞄向了工业界,得到了英特尔、英伟达等硬件平台的配合,向全球开发者免费供给AI库与工具,并在2015年推出了专门为TensorFlow框架打造的计算神经网络专用芯片TPU,引发了云端造芯的浪潮,并以每年一代的速度持续迭代。
应该说,谷歌的商业嗅觉非常灵敏,ResNet和AlphaGo一下子就点燃了工业界的激情,人工智能以熊熊大火之势席卷工业界。TensorFlow自然而然地向工业需求进行倾斜,逐步推出了TensorFlow Serving、TensorFlow Lite等产品,让客户可以在云、服务器、移动设备和 IoT 设备上进行部署。
此举却被学术界诟病连连,学者们追求的不是部署的便捷性,而是易用性。这也为身为后来者的PyTorch提供了可乘之机,凭借“易用性”的聚力一招,PyTorch在研究领域迅速站稳脚跟,大多数出版论文和开源模型都在使用 PyTorch,目前论文中的占比已经达到80%,有了和TensorFlow分庭抗礼的资格。
国外不少研究者心中,深度学习框架已经是TensorFlow和 PyTorch共天下的局面,代表了深度学习框架研发和生产中 90% 以上的用例。可将中国市场纳入讨论范畴的话,则出现了一些不同的声音。
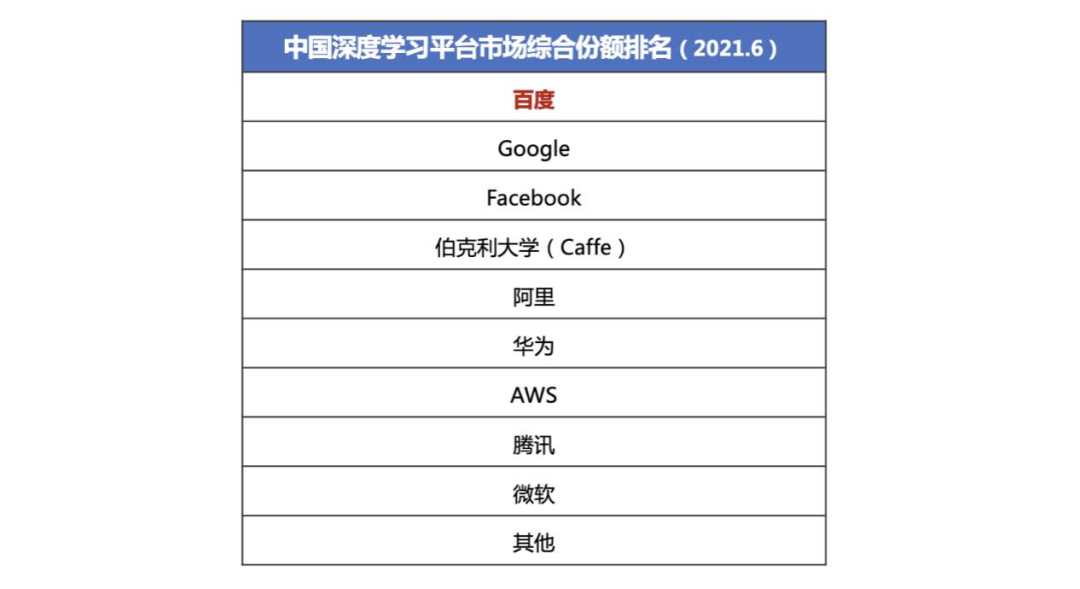
知名市场调研机构IDC曾在2020年下半年公布了一份中国深度学习框架平台市场份额的报告,TensorFlow、飞桨和PyTorch排名前三,合计占据了70%以上的份额。等到2021年上半年,IDC再次更新了市场报告,彼时百度飞桨已经超越TensorFlow位居中国市场综合份额第一。
我们曾就这份报告询问过不少开发者,对方给出的回答大多是“没想到”,再进一步的沟通后,听到最多的声音是:“原来EasyDL也是飞桨的产品。”其中被频频强调的EasyDL,是百度基于飞桨深度学习框架构建的零门槛AI开发平台,开发者上传数据并标注后,即可训练相应的模型部署应用。
考虑到中国在人才方面的巨大缺口,飞桨的市场渗透方式有着鲜明的实用主义,先让客户把AI模型用起来,哪怕他们并不知道后面还有一个深度学习框架。因为中国的大部分中小企业并不具备专业的AI算法开发能力,开发定制 AI 模型绝不是一件容易的事。可从结果导向的话,飞桨或许摸索出了不同于谷歌、Facebook的第三条路。
巨头们“闯入江湖”的连锁反应已然发生,市场份额越来越向少数几个平台集中,无论是美国还是中国,同时在便捷性、易用性、稳定性的多重指标下,算法、算力、编译器等一个都不能少,深度学习框架的门槛正变得高不可攀。
04
产业时代:中国市场“暗”流涌动
中国市场对深度学习框架的关注,在时空上迟滞了许多,直到中美科技战的爆发,相关讨论才多了起来。
相当长的一段时间里,中国开发者都是TensorFlow、PyTorch的重度拥趸,还有一些企业曾经深耕过MXNet。这里面的原因很复杂,百度的工程师文化讲求实干不张扬,飞桨在很长一段时间里专注于技术和产品,在舆论场上缺少存在感。
国内的其他互联网公司则犯了“拿来主义”的错误,要么缺少创新精神,怯于和海外的科技巨头同台竞技;要么奔着摘果子的心态,等别人探索出了眉目再跟随借鉴...... 所以在2020年以前,中国的深度学习框架屈指可数,除了百度打造的飞桨,只有小米MACE、阿里巴巴XDL在内的几个推理框架。
转机出现在2018年前后,中兴、华为等企业先后被美国制裁。当Matlab这样的老牌工具都能被禁用时,不少企业逐渐嗅到了“危险”的气息:倘若Pytorch和Tensorflow有一天重蹈Matlab的覆辙,对中国AI产业的影响无异于釜底抽薪。
深度学习框架的应用也在这个时间点进入了产业化阶段,且呈现出了两个典型的特征:一是大型模型训练,GPT-3、BERT等大模型的诞生,需要在数百台甚至数千台设备上进行训练,所瞄准的正是产业化的需求;二是可用性,TensorFlow、飞桨、PyTorch先后引入了计算图和动态图,目的是让运算更加简洁,开发者可以采用命令式的编程风格,方便进行模型的调试。
留给企业和开发者的,其实是一个三难的选择:倘若像过去那样All in国外的深度学习框架,存在着各种不确定风险;如果盲目退出国外的框架,似乎也不是理智的选择,有竞争才会有进步;何况深度学习框架属于高投入、长周期、抢生态的竞争,在产业链中承上启下的关键地位,有着统领产业进步节奏、带动终端场景与云端服务协同发展的重要作用,押错宝的代价不言而喻。
所幸最后的结果并不算糟糕。
按照百度官方的信息,目前基于飞桨开发的模型数量已经有47.6万个,不乏文心等大模型,服务的开发者数量已经达到406万,并在270多所高校开设了AI学分课程。至少可以保证在中国市场上奠定飞桨、TensorFlow、PyTorch三分天下的格局,再在市场份额分配上徐徐图谋。
进入2020年以后,清华大学计图、旷视科技天元、华为MindSpore、一流科技OneFlow相继开源,腾讯和阿里也在后面推出了PocketFlow、X-Deep Learning。如果这些新空间有能力以资金、人才等资源换时间,针对中国产业的需求因地制宜,也不排除进一步向国外框架抢夺份额的可能。
回到文初遗留的问题,在AI基础技术的角逐中,来自中国的力量确实有些孤独,很长时间里只有百度一家在搏杀。好在结果并不糟糕,在深度学习框架的“PPT”(飞桨PaddlePaddle、PyTorch、TensorFlow)格局中,已经有一个字母是来自中国,不必再面临被封杀后无计可施的境地。
05
结语
距离1956年的达特矛斯会议,已经走过了66个春秋,人工智能终于迎来了工业大生产的浪潮。来自中国的企业和科学家们,或许缺席了人工智能的过去,却在一步步锚定人工智能的未来。
目前中国已经在AI应用层站稳了脚跟,近几年的专利申请甚至超过了美国,在数据、人才、市场等方面的综合优势正在逐步显现。假如可以用深度学习框架进一步聚合开发者、资本和平台,创造有利于创新的土壤,不无可能摆脱“数字铁幕”的威胁,让中国AI在一条坚实的道路上加速奔跑。
主理人 | 张贺飞(Alter)
